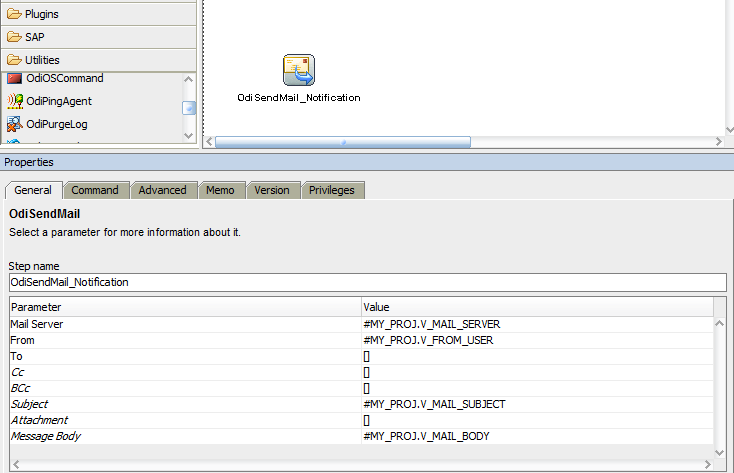
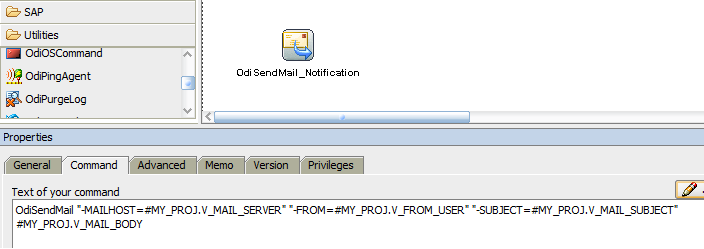
Lets take a deep dive into the parallelism capability of ODI using StartScen and Asynchronous mode.
Here is a nice article from Christophe (http://blogs.oracle.com/dataintegration/entry/parallel_processing_in_odi) that illustrates how this can be achieved.
However, the important thing to understand here is that the job kick-off process is not truly parallel.
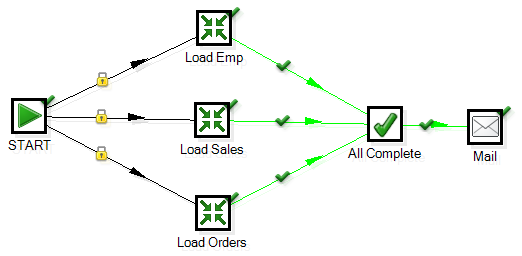
A truly parallel process should look like the following where the Start will spawn 3 parallel processes.
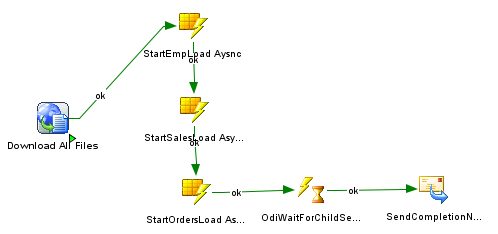
Whereas in ODI, the above behavior is mimicked by connecting jobs sequentially to each other and then executing them in Asynchronous mode.
Does the question arise - What's the difference as long as the jobs are executing in parallel ? A slight difference.
Consider a scenario when the scenario "StartEmpLoad" cannot start due to some reason (Scenario not available or Agent selected for the Scenario is down). In that case, the next (or did we say parallel) job "StartSalesLoad" will never be kicked off. Since both of them are connected with an "OK" and since the first job wasnt OK, the flow never reaches the next process. This error is a job kick-off error and is different from the data errors that would normally be encountered during a job execution (Duplicate keys, Data not found, etc).
Each StartScen in here kicks off a job and then moves on to the next StartScen. Being Async jobs, even though they dont wait for the results to come back, they do make sure that the job was kicked off successfully (vs completed successfully).

Here is a nice article from Christophe (http://blogs.oracle.com/dataintegration/entry/parallel_processing_in_odi) that illustrates how this can be achieved.
However, the important thing to understand here is that the job kick-off process is not truly parallel.
A truly parallel process should look like the following where the Start will spawn 3 parallel processes.
Whereas in ODI, the above behavior is mimicked by connecting jobs sequentially to each other and then executing them in Asynchronous mode.
Does the question arise - What's the difference as long as the jobs are executing in parallel ? A slight difference.
Consider a scenario when the scenario "StartEmpLoad" cannot start due to some reason (Scenario not available or Agent selected for the Scenario is down). In that case, the next (or did we say parallel) job "StartSalesLoad" will never be kicked off. Since both of them are connected with an "OK" and since the first job wasnt OK, the flow never reaches the next process. This error is a job kick-off error and is different from the data errors that would normally be encountered during a job execution (Duplicate keys, Data not found, etc).
Each StartScen in here kicks off a job and then moves on to the next StartScen. Being Async jobs, even though they dont wait for the results to come back, they do make sure that the job was kicked off successfully (vs completed successfully).